




In this post i will show you cool examples you can do with Google Puppeteer : The headless Chrome bundled by Chrome Lab team in Google.
Scrap data from web, test your user interfaces, render your website to check SEO related things will be covered in this post.
You want to learn what is Puppeteer and how to install it ? Check the end of this post. Now, let’s check out these examples :
Puppeteer examples :
1.Visit a website :
The first basic thing is to visit a website with Puppeteer. We set manually a viewport of 1280×800.
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 })
await page.goto('https://www.aymen-loukil.com');
await browser.close();
});
You run the file and nothing happens and that’s normal ! remember it is headless Chrome so no UI. To see what’s happening you could add this launch option to disable the headless mode in line 2. {headless:false}
puppeteer.launch({headless: false}).then(async browser => {
Oh great ! Chromium is showing up now, loading my website and then closes.
2.Take a screenshot example:
Let’s see how to take a screenshot when visiting a website with Puppeteer:
const puppeteer = require('puppeteer');
puppeteer.launch({headless: false}).then(async browser => {
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 })
await page.goto('https://www.aymen-loukil.com');
await page.screenshot({ path: 'myscreenshot.png', fullPage: true });
await browser.close();
});
page.Screenshot() can take some optional parameters. fullPage is useful to get a fullpage screenshot. What if i want to take a screenshot of a specific region in a page ? For example i want to automate screenshotting Amazon navigation header… Possible with the Clip option that has x,y coordinates and width and height parameters :
const puppeteer = require('puppeteer');
const options = {
path: 'amazon-header.png',
fullPage: false,
clip: {
x: 0,
y: 0,
width: 1280,
height: 150
}
}
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 })
await page.goto('https://www.amazon.com');
await page.screenshot(options);
await browser.close();
});
Great !

3.Mobile device emulation example:
Let’s see how to make Chrome/Chromium behave like a mobile device and then take a screenshot to see how it renders. That’s possible with “puppeteer/DeviceDescriptors”. First go to device descriptor file and choose your preferred device name. Paste the mobile device name in line 3 : const iPhonex = devices[‘iPhone X’]
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhonex = devices['iPhone X'];
puppeteer.launch({headless:false}).then(async browser => {
const page = await browser.newPage();
//We use here page.emulate so no more need to set the viewport separately
//await page.setViewport({ width: 1280, height: 800 })
await page.emulate(iPhonex);
await page.goto('https://www.homedepot.com/');
await page.screenshot({ path: 'homedepot-iphoneX.png'});
await browser.close();
});
Subscribe to my SEO newsletter now
4.Get the page title:
A tiny but useful script to get the <title> of a page.
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.com');
const title = await page.title()
console.log(title)
await browser.close();
});
5.Control keyboard example:
Let’s try to use the keyboard and type some thing with page.keyboard.type() :
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhonex = devices['iPhone X'];
(async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.emulate(iPhonex);
await page.goto('https://www.google.fr')
await page.focus('#tsf > div:nth-child(2) > div.A7Yvie.emca > div.zGVn2e > div > div.a4bIc > input')
await page.keyboard.type('i am typing using puppeteer !');
await page.screenshot({ path: 'keyboard.png' })
await browser.close()
})()
Here we are visiting google.fr with an IphoneX emulation, focus on search input field and type a query on Google then take a snap.
6.Scrap links from a website:
Let’s scrap popular and useful marketing links from Sparktoro Trending portal :
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setExtraHTTPHeaders({Referer: 'https://sparktoro.com/'})
await page.goto('https://sparktoro.com/trending');
await page.waitForSelector('div.title > a');
const stories = await page.evaluate(() => {
const links = Array.from(document.querySelectorAll('div.title > a'))
return links.map(link => link.href).slice(0, 10)
})
console.log(stories);
await browser.close();
})();
We load the page, we wait for an element to be sure of its load. Then we use page.evaluate() to grab all div.title > a elements then extract the href value of each. Line 5, we set the referer in HTTP header to avoir detecting us as a bot.
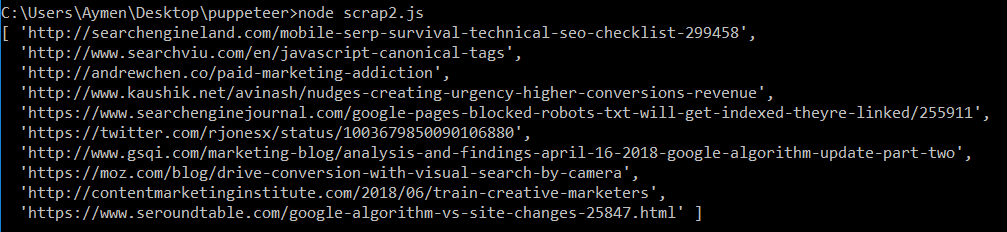
Cool ! Now you may asking yourself how to set up a proxy to avoid problems with some websites. Simple, let’s see how :
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch({args: [ '--proxy-server=127.0.0.1:3030' ], headless:false});
const page = await browser.newPage();
await page.goto('https://www.amazon.com');
await browser.close();
})();
6.Emulating Googlebot WRS for SEO:
Update: Following the remark of Eric Bidelman in Twitter, this solution won’t work. Chrome 41 has an old API so it couldn’t be controlled through Puppeteer. Thank you Eric for claryfing this.
In last SEO’campus (Paris), i talked about testing with a Googlebot look-like environment (check my slides about technical SEO). What i mean with that : Google Chrome 41 (41.0.2272.101). That’s useful to see how a website renders in that conditions and check JS or other features error. It is not 100% like Google WRS because we don’t have robots.txt support and we should also disable the features that Googlebot doesn’t support (such as indexdb, WebSQL, sessions and cookies, WebGl..etc). I will write a post for a more complete Googlebot like environment. Now we could download Google Chrome 41 from here : http://dl.google.com/chrome/win/41.0.2272.101_chrome_installer.exe
Note : If you install Chrome 41, it will automatically update to latest version. So you should turn off updates as described here : https://support.google.com/chrome/a/answer/187207 and here https://support.google.com/chrome/a/answer/187202?hl=en
After that we will tell Puppeteer the path to our preferred Chrome location using the “executablePath” parameter :
const puppeteer = require('puppeteer');
const browserFetcher = puppeteer.createBrowserFetcher();
puppeteer.launch({executablePath: 'c:/pathToChrome'}, {headless: false}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.com');
});
Check against Google features :
Eric Bidelman, Google engineer working on headless Chrome, has published a cool script checking a website againt Google WRS features and alert you if your website does implement a non supported stuff. Check the script : https://github.com/GoogleChromeLabs/puppeteer-examples/blob/master/google_search_features.js.
7.Blocking some requests hosts :
Here another useful thing with Puppeteer we can intercept HTTP requests and abort some of them depending on the request url, type..etc. We could use this feature to automate 3rd party scripts performance audit. We block scripts and see how do they actually cost on a website performance.
In this example we will block Amazon images CDN from loading:
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setRequestInterception(true);
page.on('request', request => {
//lazy way to extract domain from an URL
var match = request.url().replace('http://','').replace('https://','').split(/[/?#]/)[0];
console.log(match);
if (match === 'images-na.ssl-images-amazon.com')
request.abort();
else
request.continue();
});
await page.goto('https://www.amazon.com');
await page.screenshot({path: 'amazon-noimg.png'});
await browser.close();
})();
So here any request on images-na.ssl-images-amazon.com host will be aborted and we get an Amazon page that looks like this :
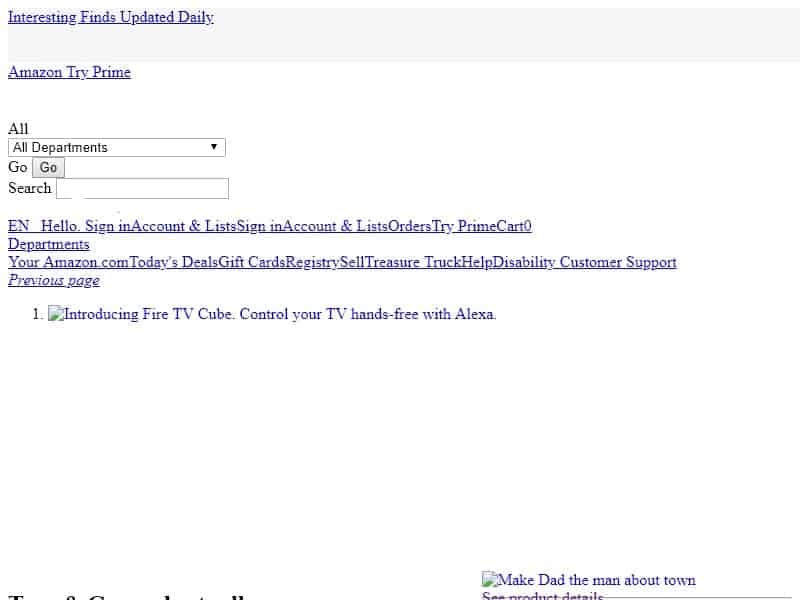
8.Disable JavaScript example:
Now we intercept requests and if the type is ‘script’ we block its loading.
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setRequestInterception(true);
page.on('request', request => {
if (request.resourceType() === 'script')
request.abort();
else
request.continue();
});
await page.goto('https://www.youtube.com');
await page.screenshot({path: 'youtube-nojs.png'});
await browser.close();
})();
So here we have Youtube without JS enabled, enjoy watching your videos !
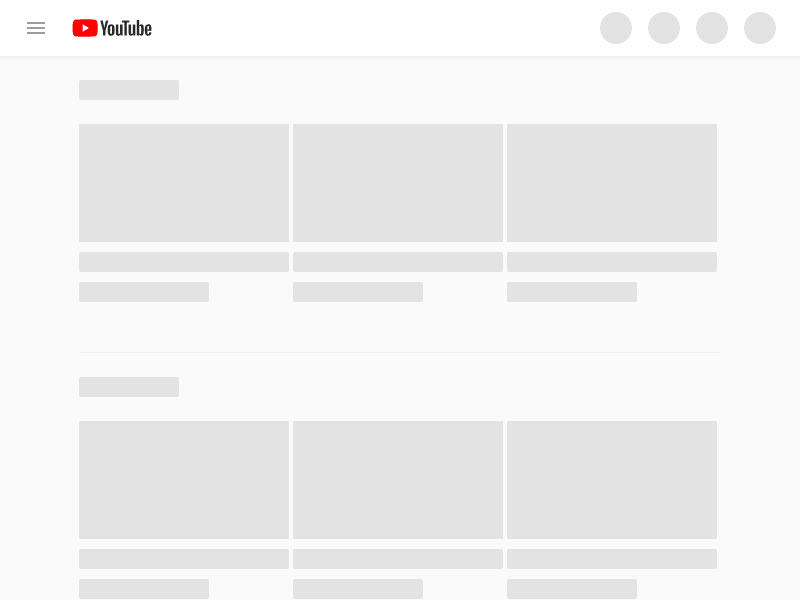
9.Get the page source code example :
You would need to grab the HTML source of a loaded page ? Puppeteer API gives you this possibility with “page.content()”
const puppeteer = require('puppeteer');
const fs = require('fs');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.youtube.com', {waitUntil: 'networkidle0'});
const html = await page.content();
//save our html in a file
fs.writeFile('page.html', html, _ => console.log('HTML saved'));
//... do some stuff
await browser.close();
})();
10.Puppeteer for UI testing, form submission automation:
Yesterday Bill asked on Twitter if people test their contact forms time to time to ensure that they still working. The fun fact : I was just writing this part of the post. So here i share with you how we can test my contact form.
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({headless:false, slowMo: 100});
const page = await browser.newPage();
//Go to my page and wait until the page loads
await page.goto('https://www.aymen-loukil.com/en/contact-aymen/', {waitUntil: 'networkidle2'});
await page.waitForSelector('#genesis-content > article > header > h1');
//type the name
await page.focus('#wpcf7-f97-p311-o1 > form > p:nth-child(2) > label > span > input')
await page.keyboard.type('PuppeteerBot');
//type the email
await page.focus('#wpcf7-f97-p311-o1 > form > p:nth-child(3) > label > span > input')
await page.keyboard.type('PuppeteerBot@mail.com');
//type the message
await page.focus('#wpcf7-f97-p311-o1 > form > p:nth-child(4) > label > span > textarea')
await page.keyboard.type("Hello Aymen ! It is me your PuppeteerBot, i test your contact form !");
//Click on the submit button
await page.click('#wpcf7-f97-p311-o1 > form > p:nth-child(5) > input')
await page.screenshot({ path: 'form.png', fullPage: true });
})();
The process is simple (i also commented the code) :
- Visit the page and wait for page load
- Focus on each element of the form and type the data
- Submit the form by clicking on the button
Note : The selectors seem to be complicated but here is how you could get any selector on any form :
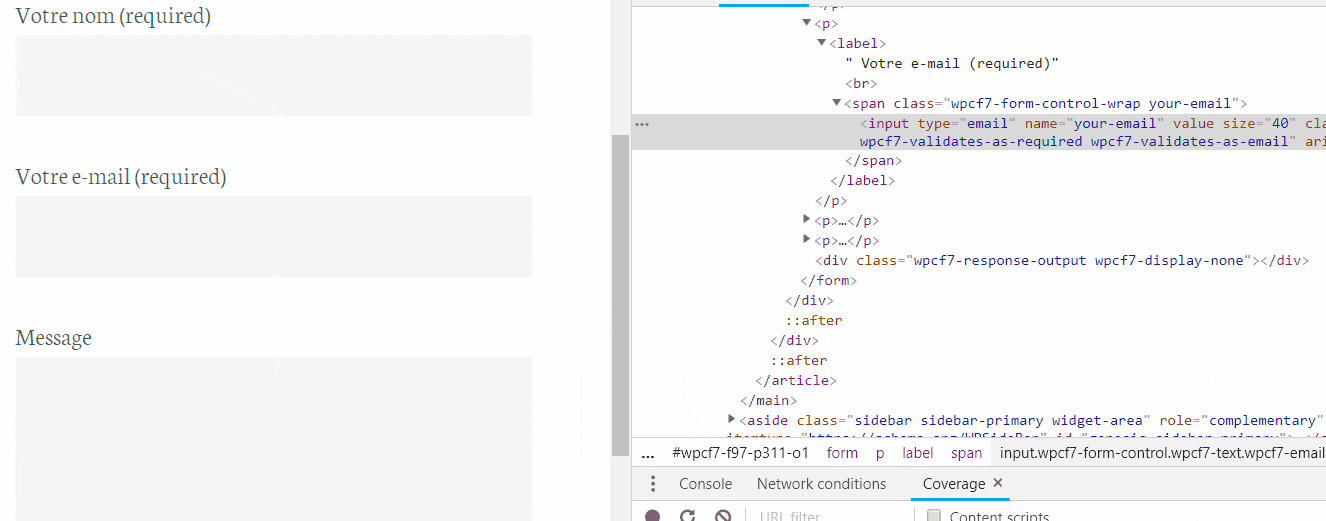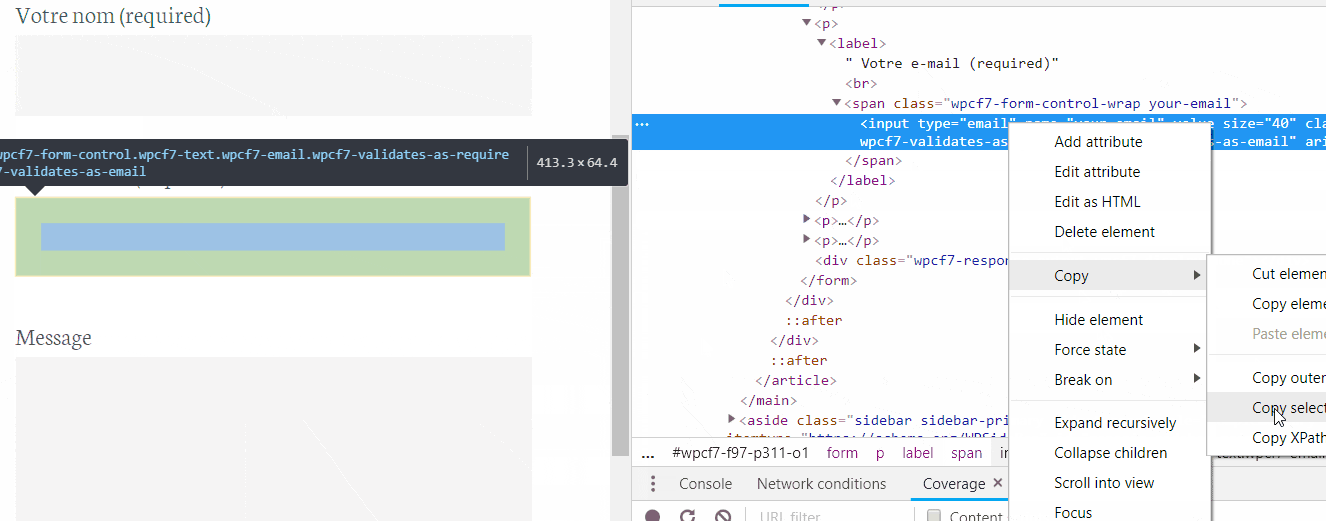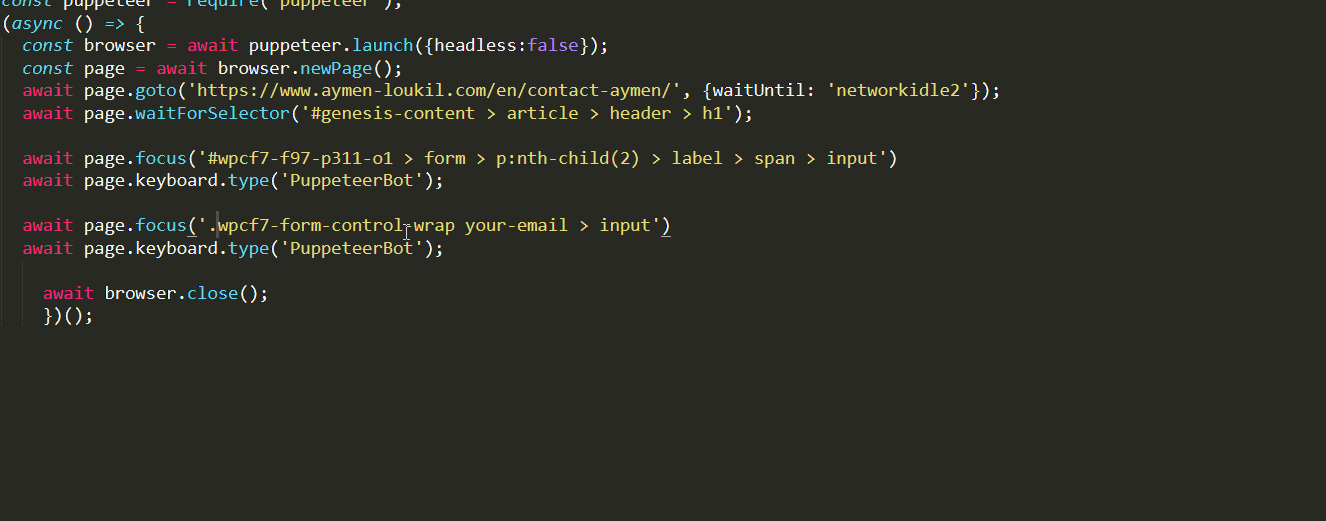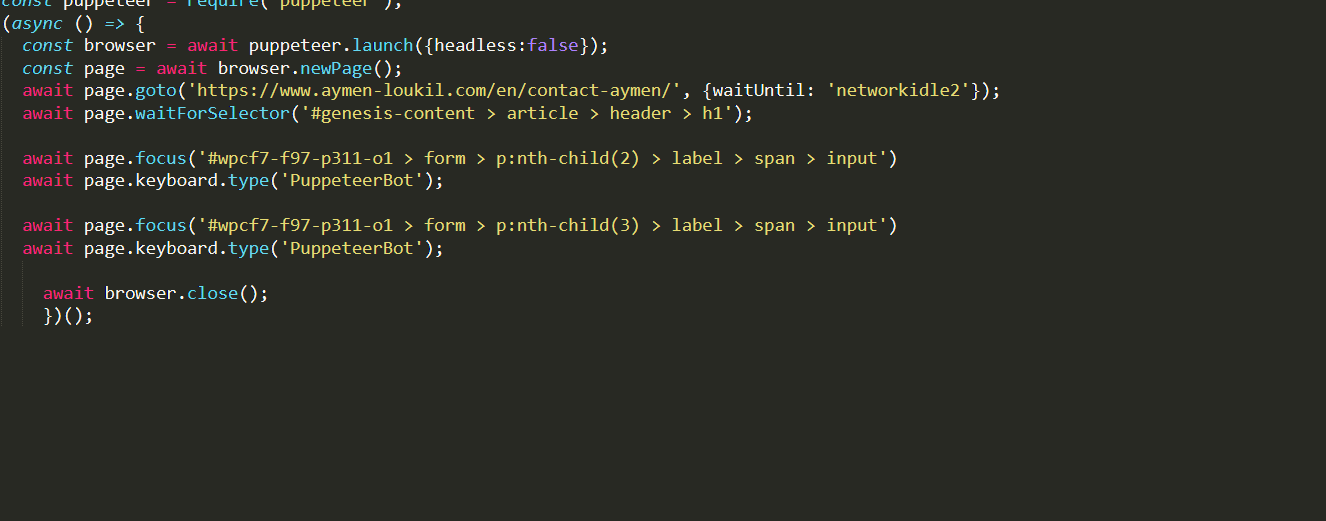
- inspect the element
- Right-click>copy selector
Useful but only for on-shot testing..It would be much better to make this run on a regular basis no ? Let’s schedule it to run every X time then :
var CronJob = require('cron').CronJob;
var job = new CronJob({
//runs every monday
cronTime: '0 10 * * *',
onTick: function() {
const puppeteer = require('puppeteer');
(async () => {
//The previous script start
const page = await browser.newPage();
//Go to my page and wait until the page loads
await page.goto('https://www.aymen-loukil.com/en/contact-aymen/', {waitUntil: 'networkidle2'});
await page.waitForSelector('#genesis-content > article > header > h1');
//type the name
await page.focus('#wpcf7-f97-p311-o1 > form > p:nth-child(2) > label > span > input')
await page.keyboard.type('PuppeteerBot');
//type the email
await page.focus('#wpcf7-f97-p311-o1 > form > p:nth-child(3) > label > span > input')
await page.keyboard.type('PuppeteerBot@mail.com');
//type the message
await page.focus('#wpcf7-f97-p311-o1 > form > p:nth-child(4) > label > span > textarea')
await page.keyboard.type("Hello Aymen ! It is me your PuppeteerBot, i test your contact form !");
//Click on the submit button
await page.click('#wpcf7-f97-p311-o1 > form > p:nth-child(5) > input')
await page.screenshot({ path: 'form.png', fullPage: true });
//The previous script end
})();
},
start: false,
timeZone: 'Europe/London'
});
job.start();
Here we are using the npm module ‘cron’. We schedule the script to run every Monday on 10 Am so we will receive a testmail.
11.Automate code coverage check:
After my last talk about webperformance, many of you asked me about automating code coverage check in order to integrate it with your CI for example. You can check for it manually through Chrome Dev Tools console or Google Lighthouse performance audit.
So here is a script to do it :
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
//start coverage trace
await Promise.all([
page.coverage.startJSCoverage(),
page.coverage.startCSSCoverage()
]);
await page.goto('https://www.cnn.com');
//stop coverage trace
const [jsCoverage, cssCoverage] = await Promise.all([
page.coverage.stopJSCoverage(),
page.coverage.stopCSSCoverage(),
]);
let totalBytes = 0;
let usedBytes = 0;
const coverage = [...jsCoverage, ...cssCoverage];
for (const entry of coverage) {
totalBytes += entry.text.length;
for (const range of entry.ranges)
usedBytes += range.end - range.start - 1;
}
const usedCode = ((usedBytes / totalBytes)* 100).toFixed(2);
console.log('Code used by only', usedCode, '%');
await browser.close();
});
Result :

12.Make a Devtool tracing:
Last (for this post) cool stuff we can do with Puppeteer is to record a tracing and save it. The saved Json file could be imported by Chrome to audit performance and scripting issues.
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const iPhonex = devices['iPhone X'];
(async () => {
const browser = await puppeteer.launch()
const page = await browser.newPage()
await page.emulate(iPhonex);
//start the tracing
await page.tracing.start({path: 'trace.json',screenshots:true});
await page.goto('https://www.bmw.com')
//stop the tracing
await page.tracing.stop();
await browser.close()
})()
To do it open Chrome devtools > Performance and click on the up arrow button and open the JSON file.
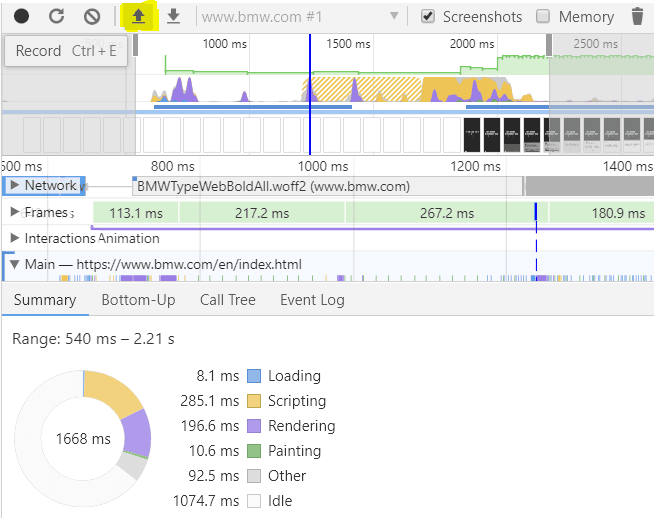
Second choice : drag and drop it online here : https://chromedevtools.github.io/timeline-viewer/
What is a puppeeteer ?
According to Wikipedia : A puppeteer is a person who manipulates an inanimate object that might be shaped like a human, animal or mythical creature, or another object to create the illusion that the puppet is “alive”. With Google Puppeteer, the same concept, Google Chrome is the puppet that we will manipulate to do some tasks on web.
Google Puppeteer :
In the officiel Github repository we read : “Puppeteer is a Node library which provides a high-level API to control headless Chrome or Chromium over the DevTools Protocol. It can also be configured to use full (non-headless) Chrome or Chromium”. Ok so we will use Node.js, JavaScript to command one (or many) instance of Google Chrome or Chromium.
Google Puppeteer use cases :
Puppeteer is useful for :
StealingScraping content from websites and web applications;- Automate tasks on web pages : form submission, keyboard and mouse emulation;
- Web and UI testing : automated tests, browser features tests, compatibility with Chrome versions;
- Taking screenshots and exporting web pages as PDF;
- Rendering website with a look-like Googlebot WRS for SEO [Chrome 41 + Googlebot features];
- Auditing web performance stuff with Headless Chrome and debugging issues;
- Any thing (almost) Google Chrome can do and your imagination is the limit.
Google Puppeteer API architecture :
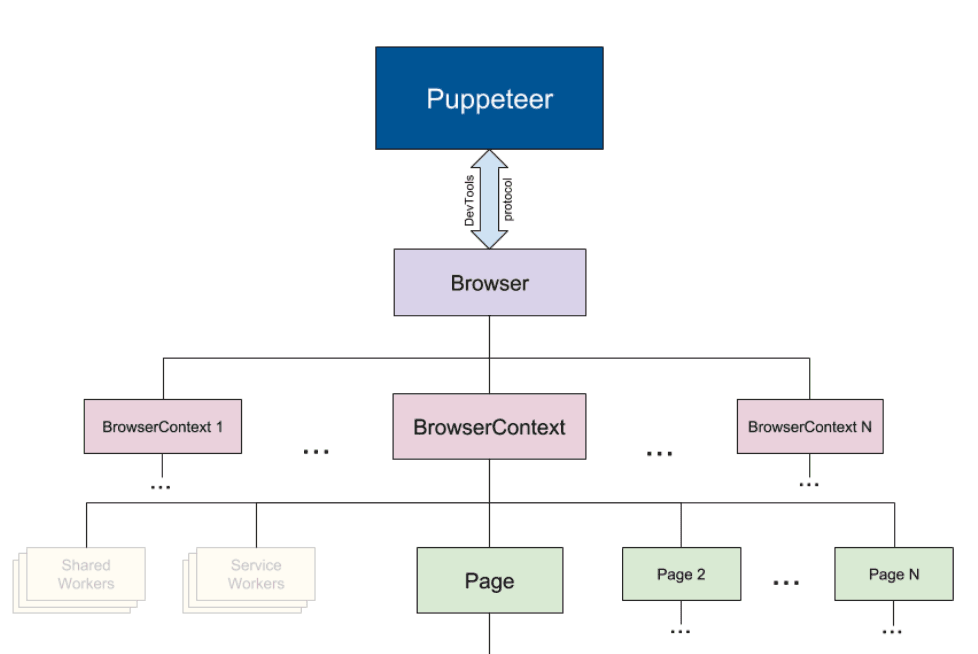
Puppeteer communicates with the browser via DevTools protocol to have access to BrowserContext(s) (navigation session) and the associated open pages and their objects..etc
How to Install Google Puppeteer :
Let’s install Puppeteer and start our tutorial. First thing you need to install Node.js (I guess if you do not know what Node is, you’ve already left this page :D). Then, open your Node command prompt and type : “npm install puppeteer”
Final thoughts about this Google Puppeteer tutorial :
- Puppeteer is very useful for several task types on the web (crawling, testing, debugging, scrapping, automation..Etc)
- The Puppeteer API is kind of simple to understand and to get started with (Good job team)
- Headless Browser automation is a must learn thing for SEOs, developers, and marketing crew
Useful links :
Try Puppeteer online : https://try-puppeteer.appspot.com/
Puppeteer documentation : https://pptr.dev/
Subscribe to my newsletter to get more SEO tips and tutorials
International SEO Consultant



Awesome blog 🙂
I followed your explanation and successfully scrapped a page using puppeteer.
Cool ! Glad that my tutorial helped.
How can one enter the text from a CSV file into a search bar field?
Yes it is possible. This is for you : https://www.npmjs.com/package/csv-parser
very good example for beginners…Thanks a lot
Really good!
Just a quick question, is there a good way to config different environments ? Like test on prod with different urls to navigate to ?
Thanks!
I think you have mentioned some very interesting points,
regards for the post.
Using pupeteer , I want to test if an application executes its functionality correctly when data is copied from an Excel sheet into the browser window of the application.I am able to read data from the Excel sheet, but not able to copy that data into the clipboard and then paste it into the browser window.
How we can send email from Outlook using puppeteer..also are assertions can be applied here? Do you think it can replace selenium.